

Connect Visual Paradigm to Microsoft Fabric Lakehouse
Visual Paradigm support connect to Microsoft Fabric Lakehouse to perform database engineering. In this article you will learn how to establish connection with Microsoft Fabric Lakehouse.
Visual Paradigm support connect to Microsoft Fabric Lakehouse to perform database engineering. In this article you will learn how to establish connection with Microsoft Fabric Lakehouse.
When trying to generate DDL for my entity model the following error prompt and complain identity key generator is not supported.
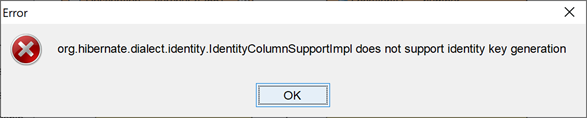
Generate DDL for Oracle complain identity key generator is not supported
Visual Paradigm support connect to various database server to perform database engineering, including forward and reverse engineering between database and entity relationship diagram (ERD). During the process user will need to connect Visual Paradigm with their database via JDBC connection. A JDBC driver file will involve in the database connection setting. For team environment you can configure the database connection using a reference file path to load the JDBC driver from developer’s environment. In this article we will teach you how to make use of reference file path to specify JDBC driver location when establish database connection.
By default SQL Server will store all your database objects, system objects, tables, stored procedures, etc… into the primary file group. This basically is putting everything into a single data file (.mdf) and transaction log (.ldf). This should be pretty sufficient in development environment. But in production environment the default setting could causing performance limitation. To achieve higher throughput we can design the database to work with multiple files and filegroups.
The database index helps to improve the performance on data retrieval on the database tables. The index allows database engine locate the required data without having to search in every record in the database table. When defining index for tables in Visual Paradigm, by default the index name will be automatically generated according to a predefined pattern and it is not editable by user.
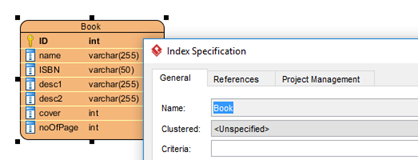
Index name was automatically filled and cannot be modify
The calculated column in database (also call generated column in some databases) allow users to define an expression for calculating values by using data from other columns. This saving user effort to obtain the values in desired form by let the DBMS handling it. In Visual Paradigm you can define the expression for calculated column by using the User Type. To create calculated column: Read more
 Visual Paradigm support wide range of databases for user to model the data structure of their systems. Once the data model is done you can generate persistent layer source code in Hibernate and use it as the out-of-the-box data access layer for building your database applications. All the data types which covered by Hibernate are directly supported by Visual Paradigm. But what if your model involved some domain specific data type which not covered by Hibernate? In this case you can make use of the User Type property to model it. To model with non-supported column types:
Visual Paradigm support wide range of databases for user to model the data structure of their systems. Once the data model is done you can generate persistent layer source code in Hibernate and use it as the out-of-the-box data access layer for building your database applications. All the data types which covered by Hibernate are directly supported by Visual Paradigm. But what if your model involved some domain specific data type which not covered by Hibernate? In this case you can make use of the User Type property to model it. To model with non-supported column types:
You may receive error complain fail to download JDBC driver when configuring database connection for your Visual Paradigm project.
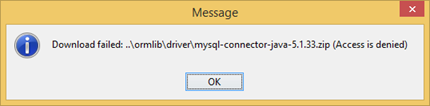
Access denied when download JDBC Driver
 The database modeling tool in Visual Paradigm allow user to design and model database with Entity Relationship Diagram (ERD). Besides modeling of database, you can also generate Database Definition Language (DDL) from your ERD. Unless you would like to generate DDL for altering the database, otherwise it is not necessary to setup connection with your database in order to generate DDL. You can simply pick the default database for your project, and let VP generate the database creation statement for you. Read more
The database modeling tool in Visual Paradigm allow user to design and model database with Entity Relationship Diagram (ERD). Besides modeling of database, you can also generate Database Definition Language (DDL) from your ERD. Unless you would like to generate DDL for altering the database, otherwise it is not necessary to setup connection with your database in order to generate DDL. You can simply pick the default database for your project, and let VP generate the database creation statement for you. Read more
![]() Visual Paradigm’s Open API is a powerful tool which allow user to extend the functionalities of Visual Paradigm software. With Open API you can generate DDL from ER models in your project. The generation of DDL include 4 major steps and this article will explain to you in details. To generate DDL with Open API:
Visual Paradigm’s Open API is a powerful tool which allow user to extend the functionalities of Visual Paradigm software. With Open API you can generate DDL from ER models in your project. The generation of DDL include 4 major steps and this article will explain to you in details. To generate DDL with Open API: